一、说明介绍与机场推荐
全球节点更新啦!涵盖美国、新加坡、加拿大、香港、欧洲、日本、韩国等地,提供10个全新订阅链接,轻松接入V2Ray/Clash/小火箭等科学上网工具,简单复制、粘贴即畅享全球网络自由!只需复制以下节点数据,导入或粘贴至v2ray/iso小火箭/winxray、2rayNG、BifrostV、Clash、Kitsunebi、V2rayN、V2rayW、Clash、V2rayS、Mellow、Qv2ray等科学上网工具,即可直接使用!
二,自用机场推荐
包月(不限时)最低5元起150GB流量:点我了解详情
同步电报群:https://t.me/xfxssr
永久发布页地址,防丢失https://sulinkcloud.github.io/
三,节点列表和测试速度










clash verge 测试速度超快,看油管4k无压力
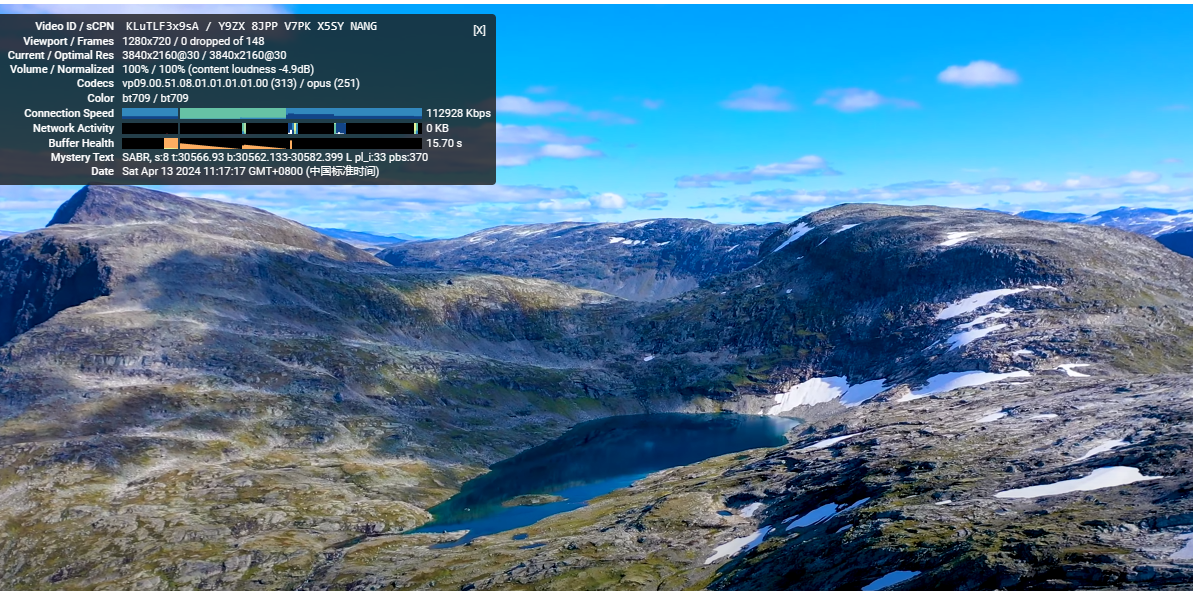
200个免费节点分享

分割线
如何用 Python 编写一个简单的网络爬虫?
解答步骤:
安装必要库:打开 CMD,输入pip install requests beautifulsoup4 lxml。
导入库:在 Python 文件中写入:
python
import requests
from bs4 import BeautifulSoup
发送 HTTP 请求:
python
url = “https://example.com” # 目标网站
headers = {“User-Agent”: “Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6”}
response = requests.get(url, headers=headers)
response.encoding = ‘utf-8’ # 处理中文编码
解析 HTML:
python
soup = BeautifulSoup(response.text, ‘lxml’)
# 提取标题:soup.title.text
# 提取所有链接:for a in soup.find_all(‘a’): print(a.get(‘href’))
保存数据:
python
with open(‘data.txt’, ‘w’, encoding=’utf-8′) as f:
f.write(soup.text)
异常处理:添加 try-except 块防止请求失败,设置请求延迟time.sleep(1)避免频繁请求被封 IP。
评论